상표 유사도 판별 학습 데이터와 판별 알고리즘 특허 출원
상표 유사도 판별 알고리즘 특허 출원 및 등록 완료
특허 제10-2234385호 (2021년 3월 25일 등록): 상표 검색 방법 및 장치
특허 제10-2234385호 (2021년 3월 25일 등록): 상표 검색 방법 및 장치
상표 이미지 데이터의 중복 문자 상표 등을 제거하고
자체적인 학습 데이터 기준인 도형 분류표를 작성하여 242분류,
24,200개의 이미지에 대한 라벨링을 통해 학습 데이터 확보
자체적인 학습 데이터 기준인 도형 분류표를 작성하여 242분류,
24,200개의 이미지에 대한 라벨링을 통해 학습 데이터 확보
상표 유사도 판별 알고리즘 특허 출원제10-202-0181278호 (2020년 12월 22일 출원, 미공개)
상표 검색 모델 및 상표 검색 모델의 학습 방법 특허출원제10-2021-0038827호(2021년 3월 25일 출원, 미공개)
NIA 한국정보화진흥원
2020 인공지능 학습용 데이터 음성 분야 의미정확성 검수
각 기업에서 구축한 AI 학습용 음성 데이터 구축의 결과물을 검사하여,
검사 대상 업체별 품질 수준을 확인함으로써 AI 학습용 데이터의 품질을 향상시켰습니다.
검사 대상 업체별 품질 수준을 확인함으로써 AI 학습용 데이터의 품질을 향상시켰습니다.
수행 과정
크라우드 소싱 플랫폼을 활용하여 어노테이션의 의미적 정확도를 검사하여
단기간에 대량의 검사를 수행하였습니다.
단기간에 대량의 검사를 수행하였습니다.
서로 다른 두 사람이 1차 및 2차 검사를 수행하고
두 결과가 상이한 경우 3차 검사를 수행함으로써 검사의 신뢰도를 제고하였으며,
언어학 전문가와 인공지능 전문가의 자문을 통해 검사 항목에 대한 전문성을 확보하였습니다.
두 결과가 상이한 경우 3차 검사를 수행함으로써 검사의 신뢰도를 제고하였으며,
언어학 전문가와 인공지능 전문가의 자문을 통해 검사 항목에 대한 전문성을 확보하였습니다.
STEP1
데이터 소스

STEP2
데이터 검수

STEP3
AI Hub 업로드

NIA 한국정보화진흥원
2021 인공지능 학습용 데이터 구축 사업 - 외국인 한국어 발화 음성 데이터 구축
다문화 가정 주민, 외국인 근로자, 유학생 등 국내 체류 외국인 수의 꾸준한 증가 및 한류의 영향으로
전 세계적으로 한국어를 학습하고자 하는 외국인의 수요가 증가하였습니다.
전 세계적으로 한국어를 학습하고자 하는 외국인의 수요가 증가하였습니다.
하지만 현재 개발된 인공지능 한국어 음성인식 기술은 외국인의 한국어 발화 음성을 인식하는 데에 어려움이 있어,
인공지능에 외국인의 한국어 발음과 한국어 표준 발음을 학습시켜 외국인의 한국어 음성을 인식할 수 있는
음성인식 모델 개발의 필요성이 증가하였습니다.
인공지능에 외국인의 한국어 발음과 한국어 표준 발음을 학습시켜 외국인의 한국어 음성을 인식할 수 있는
음성인식 모델 개발의 필요성이 증가하였습니다.
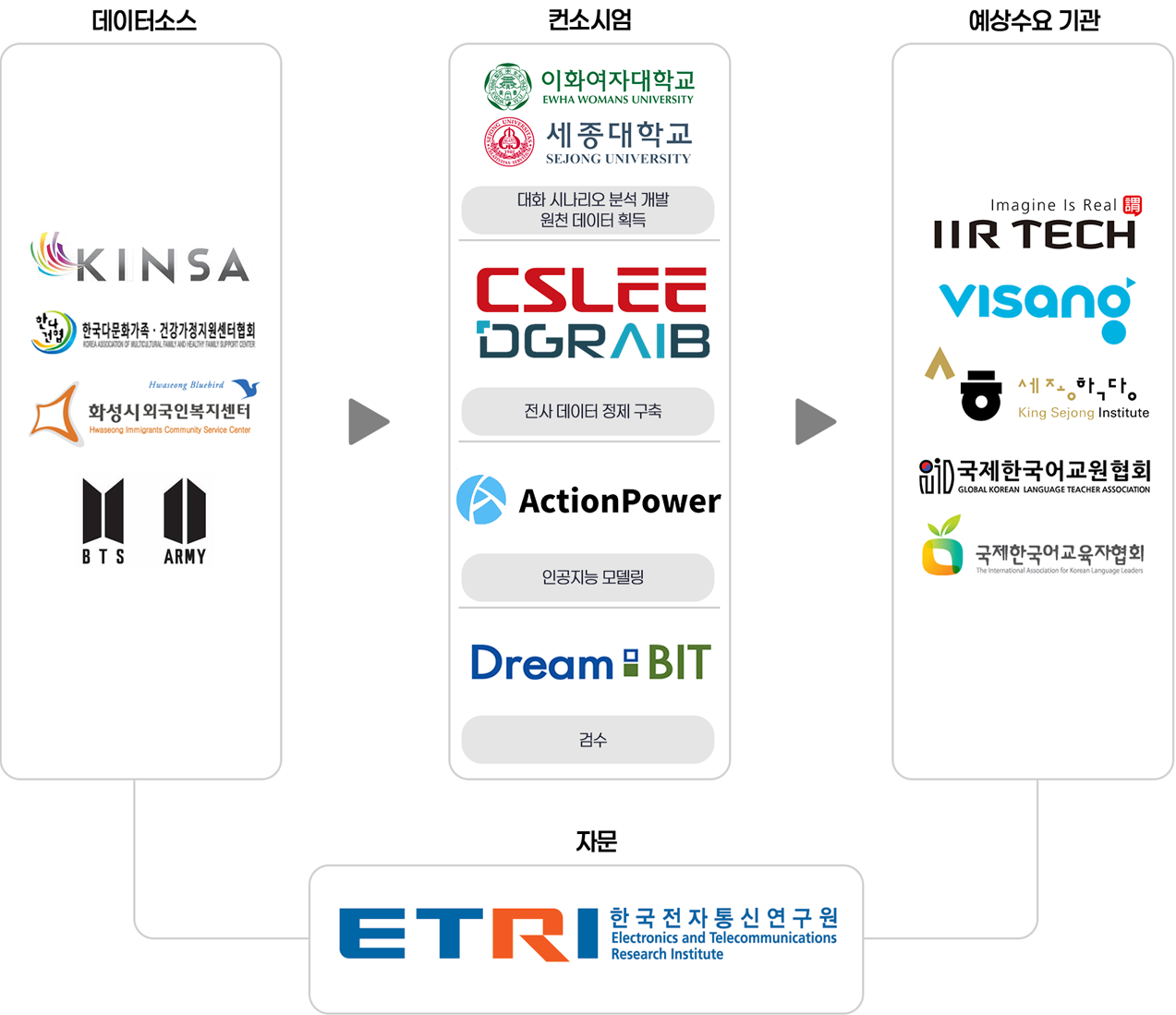
이에 따라, (주)드림비트는 분야별 최고 전문기관과 함께, 모델에 활용할 국내 체류 외국인 2,000명 대상,
모국어별 5개 그룹 4,000시간 이상의 외국인 한국어 발화 음성 데이터를 구축하였습니다.
모국어별 5개 그룹 4,000시간 이상의 외국인 한국어 발화 음성 데이터를 구축하였습니다.
- 전과정
목표 -
전사 품질관리 통해 국내 최고수준 음성데이터 구축
4,400시간 수집 목표 달성 및 품질 기준 만족하는 4,000시간 이상의 음성데이터 최종 구축
앱 개발을 통한 음성 데이터 품질 수준 최종 검증
- 검수 단계
품질 확보 -
전수 검사를 통한 데이터 품질 확보
데이터 전수 검사를 통해 일부가 아닌, 전체 데이터의 품질 검사 진행 및 품질 확보
- 정제/전사 단계
저 품질 선별 -
2+1 전사 과정을 통한 저품질 데이터 제거
전문가 자문 받은 품질 검증 기준 수립
3명의 검사자 품질 검수 통해 데이터 품질 확인
- 수집 단계
품질 향상 -
녹음 품질 지표 관리를 통한 전 과정 품질 측정 관리
외국인 화자 녹음 시, 한국어 강사 혹은 커뮤니티 리더가 동석하여
입력 내용을 교정하는 프로세스 선정
녹음 품질 지표로 스크립트 지문 길이, 법 제도 절차, 보안 사항,
개인정보 동의 확인, 데이터 불균형 등 점검 진행
베트남어 700시간, 영어 100시간, 일본어 700시간, 중국어 1,000시간, 태국어 500시간, 기타 1,000시간 이상
총 4,000시간 이상
- 데이터 활용 예시
-
한국어 튜터링 플랫폼
한국어 음성을 통해 회화 실력 및 한국어 교육을 향상시키기 위한 한국어 튜터링 어플리케이션 개발
이점
숏클립 영상을 활용하여 상황에 맞는 표현들을 직접 보고 읽으며 학습
음성 인식 알고리즘을 통해 틀린 발음을 표시하여 바로 다시 듣기와 재녹음 진행
실시간 음성 채팅 후 스크립트와 발음 정확도 제공늘어나는 다문화 가족과 K-pop, K-drama 등의 K-팬덤들에게 손쉽게 한국어 교육 기회 확장

-
한국어 음성 인식 민원 처리 키오스크
한국에 거주 중인 외국인 및 노년층 등을 대상으로 한국어 음성 인식 민원 처리 키오스크 개발
이점
한국어 음성인식 후 민원 담당자 및 위치 안내
사용자의 선택사항으로 통역봉사자 매칭 서비스 제공키오스크를 통해 대면 처리 시간 절약
맞춤형 민원서비스 제공